



Remarque : La vidéo suivante a été enregistrée sur la version précédente de Picsellia, tandis que cet article de blog actuel a été mis à jour avec la dernière interface de Picsellia et les dernières fonctionnalités MLOps pour la vision par ordinateur (Mise à jour : 17 mars 2022)
En introduction, nous présenterons brièvement les algorithmes YOLO. Pour ceux qui ne savent pas ce qu’est YOLO, c’est l’un des algorithmes de détection d’objets les plus connus qui obtient des résultats de pointe depuis plusieurs années maintenant.
Le but de ce tutoriel est de vous apprendre à entraîner un YOLOv5 facilement, en utilisant notre plateforme MLOps de bout en bout en vision par ordinateur. Mais d’abord, nous aborderons rapidement sa théorie. Cet article se présentera comme suit :
- Évolution des détecteurs d'objets
- Qu'est-ce que YOLO et en quoi est-il différent des autres détecteurs d'objets
- Comment ça marche
- YOLO v5 en profondeur
- Comment entraîner YOLO v5 sur votre dataset personnalisé
Commençons !
Évolution des détecteurs d'objets
Il existe quelques types de détecteurs d'objets, R-CNN et SSD.
Les R-CNN sont des réseaux de neurones convolutifs basés sur une région. Ceux-ci sont plus anciens et constituent un exemple de détecteurs à deux étages. Les deux étapes sont une recherche sélective qui propose une région, c'est-à-dire des cadres de délimitation pouvant contenir des objets ; et un CNN utilisé pour classer cette région. Comme vous pouvez le voir sur la figure suivante, les deux étapes se font séquentiellement, ce qui peut prendre beaucoup de temps.

Le problème est que la première mise en œuvre de R-CNN en 2013 a été très lente. Cela laissait beaucoup de marge d’amélioration, et c’est ce qui a été réalisé en 2015 avec Fast R-CNN, puis Faster R-CNN. Ceux-ci ont remplacé l'étape sélective par le Region Proposal Network (RPN), faisant finalement de R-CNN un détecteur d'objets Deep Learning de bout en bout.
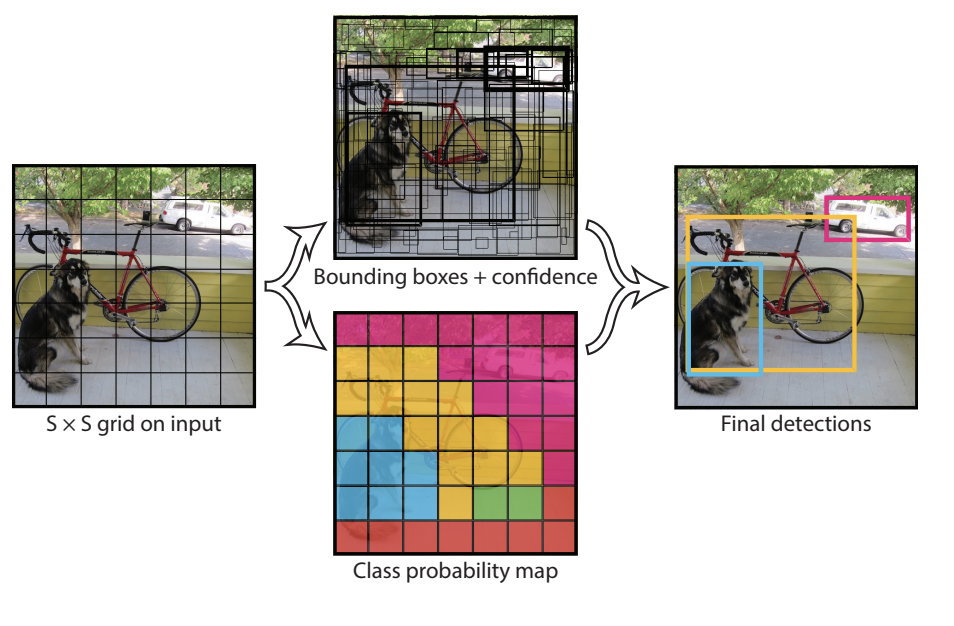
Cette famille de détecteurs donne généralement des résultats assez précis, mais est assez lents. Pour cette raison, les chercheurs ont mis au point une architecture différente appelée Single Shot Detectors (SSD), dont YOLO fait partie.
CHRONOLOGIE DU SSD
- 2015 : YOLO (You Only Look Once)
- 2016 : YOLO 9000
- 2018 : YOLO v3
- 2020 : YOLO v4
- 2020 : YOLO v5
Qu'est-ce qui rend ces algorithmes rapides ?
Ils apprennent simultanément les coordonnées de l’objet mais aussi les classes correspondantes. Ils sont moins précis que R-CNN mais beaucoup plus rapides. C’est la philosophie derrière YOLO et les nombreuses itérations connues au fil des ans.
Aujourd’hui nous allons nous concentrer sur le dernier en date, YOLO v5. Comme vous pouvez le voir dans le graphique suivant, il fonctionne vraiment bien, même face à une dette efficace, qui est exponentiellement plus lente à mesure que vous en choisissez une version supérieure.
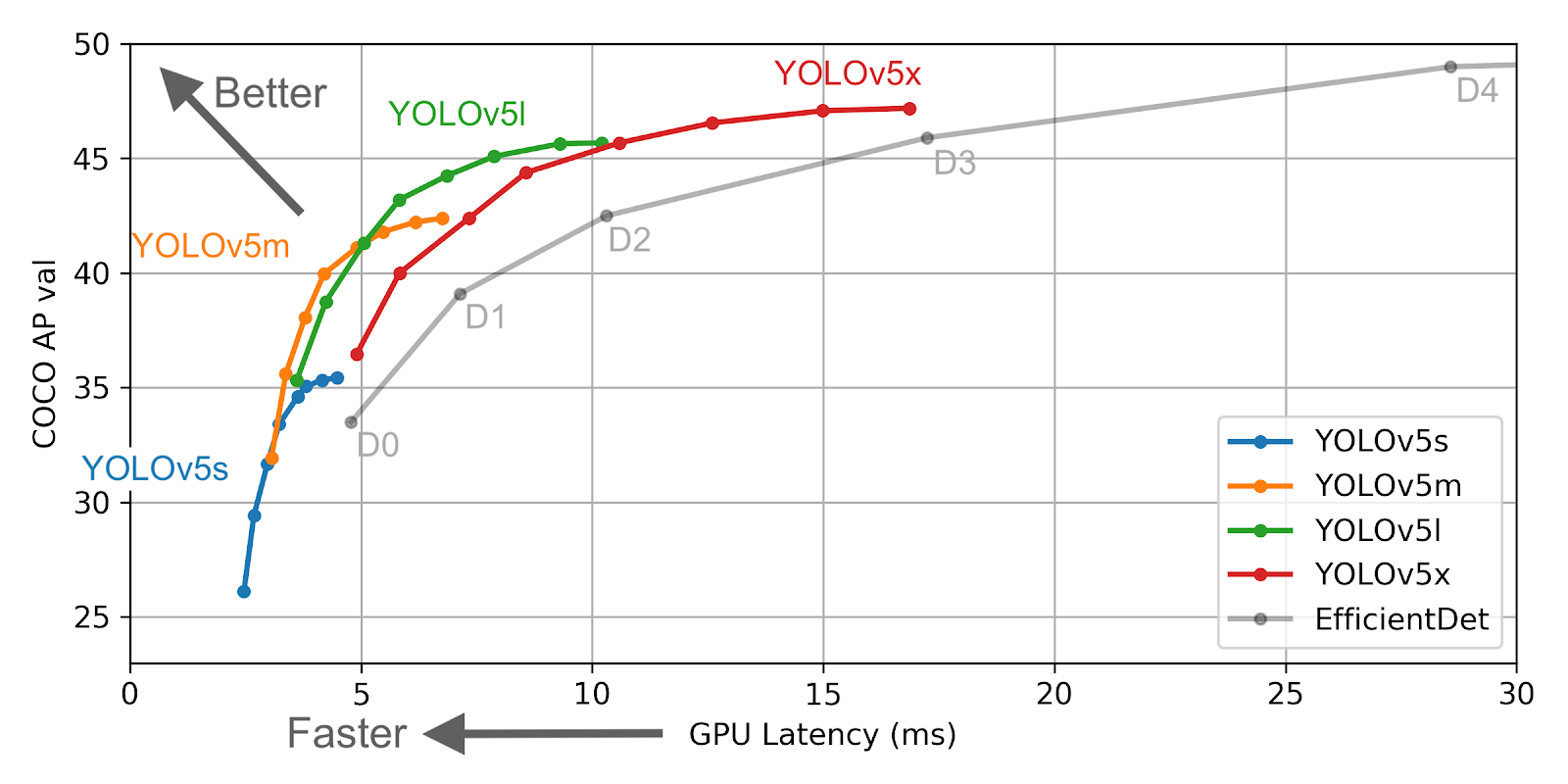
À quoi ressemblent les performances ?
Avantages
- Beaucoup plus rapide que les détecteurs basés sur R-CNN
- Performances SOTA aujourd'hui avec YOLO v5
Les inconvénients
- Légèrement moins précis que R-CNN
Comme nous pouvons le voir ensuite, il existe plusieurs versions de YOLO v5 lui-même. Il va des petites aux très grandes tailles, avec des différences évidentes en termes de poids, de performances et de latence. C'est une bonne nouvelle car on peut choisir une version soit très rapide, mais moins précise ; ou des versions qui sont de bons compromis entre latence et précision, et une version plus lourde qui sera plus performante.
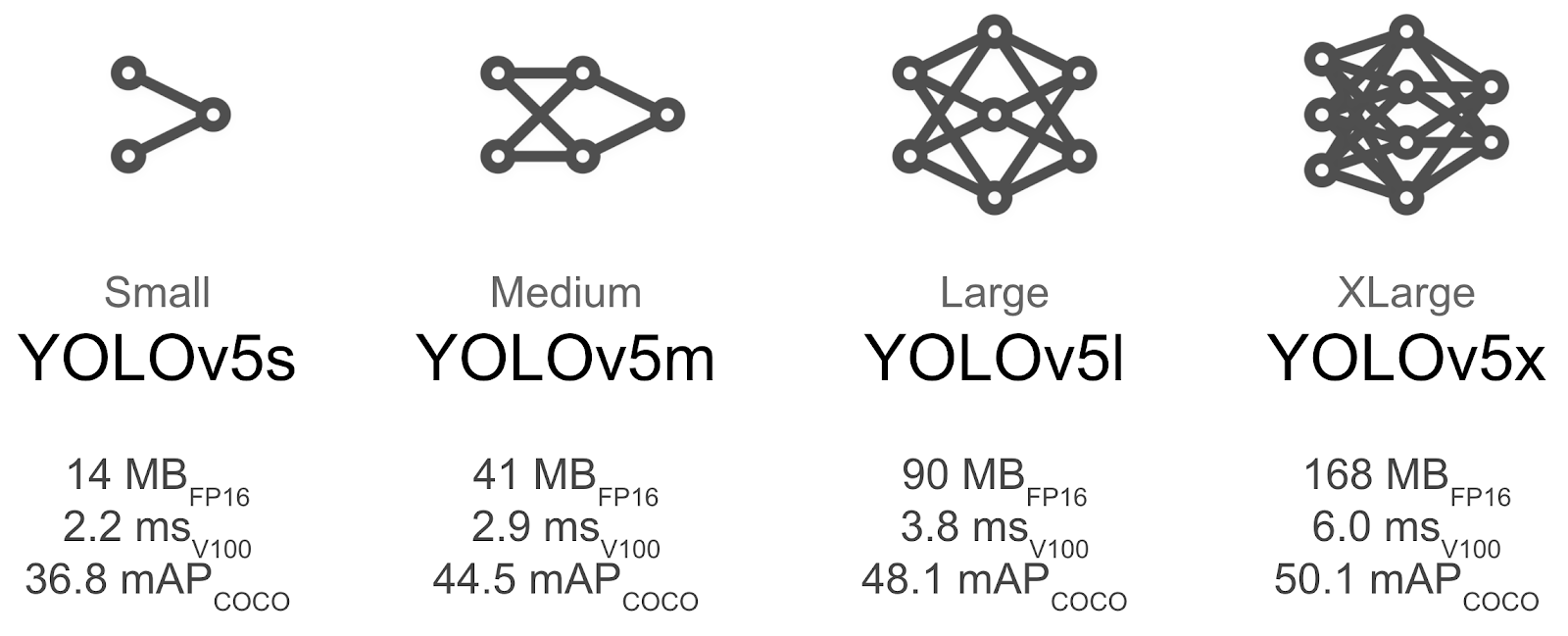
Maintenant que nous avons abordé un peu YOLO et les principales différences avec d’autres algorithmes, entraînons-le !
Comment entraîner YOLOv5 sur un ensemble de données personnalisé
Pour mémoire, Picsellia est une plateforme de développement MLOps de bout en bout qui vous permet de créer et de versionner des ensembles de données, d'annoter vos données d'IA, de suivre vos expériences et de créer vos propres modèles. De plus, sa dernière version vous permet de déployer et de surveiller vos modèles et d'orchestrer des pipelines pour automatiser vos flux de travail d'IA, le tout au même endroit.
Si vous souhaitez en savoir plus, n'hésitez pas à consulter notre Documentation, ou planifiez un appel rapide ici avec notre équipe.
Sans plus tarder, commençons !
1. Créez le dataset
Voici à quoi ressemble l'interface d'annotation. Nous choisirons un dataset de raisin de cuve pour notre projet de détection d'objets.
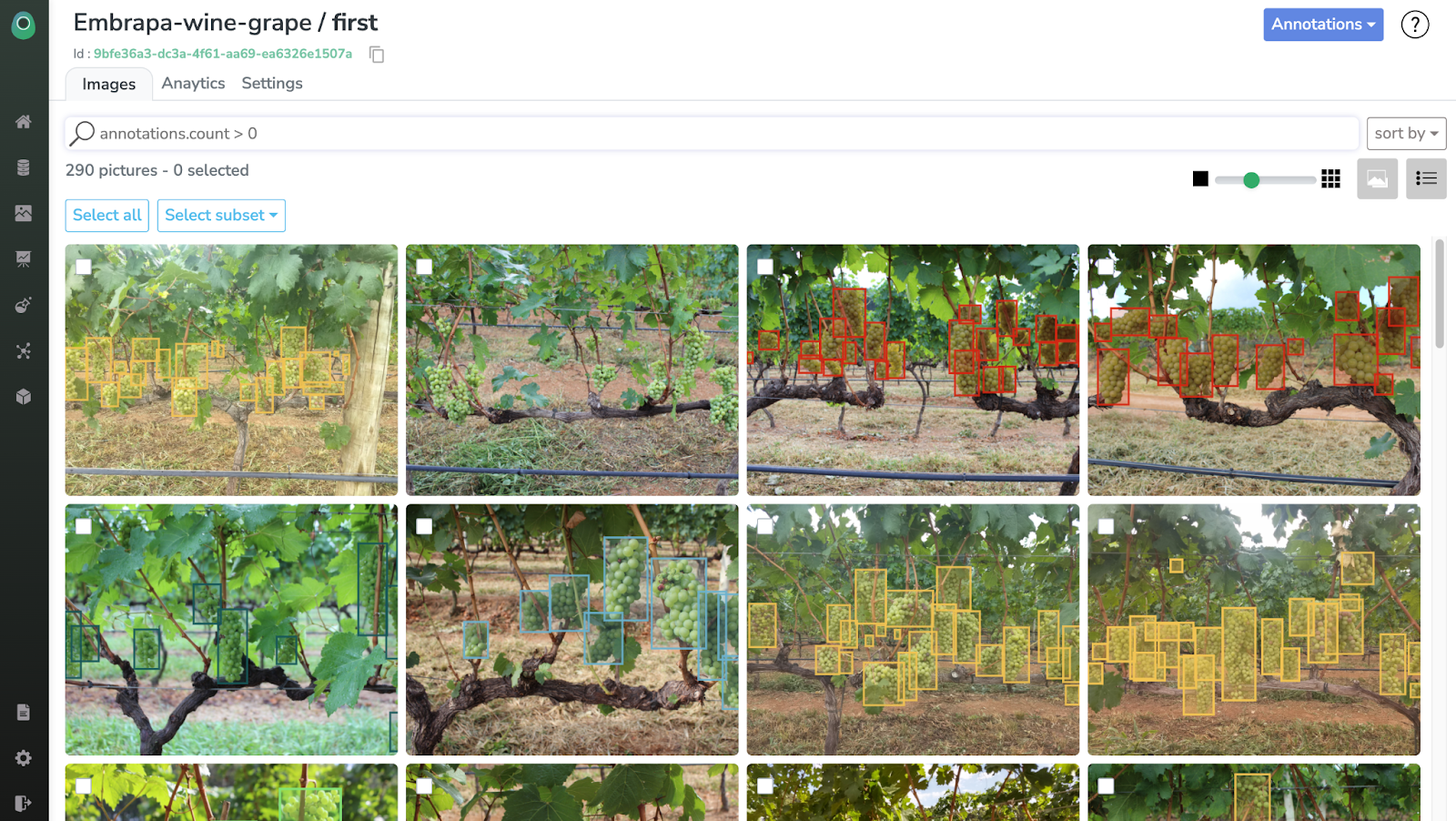
Nous pouvons trier l'ensemble de données de cette façon pour voir plus de détails, comme indiqué ci-dessous.
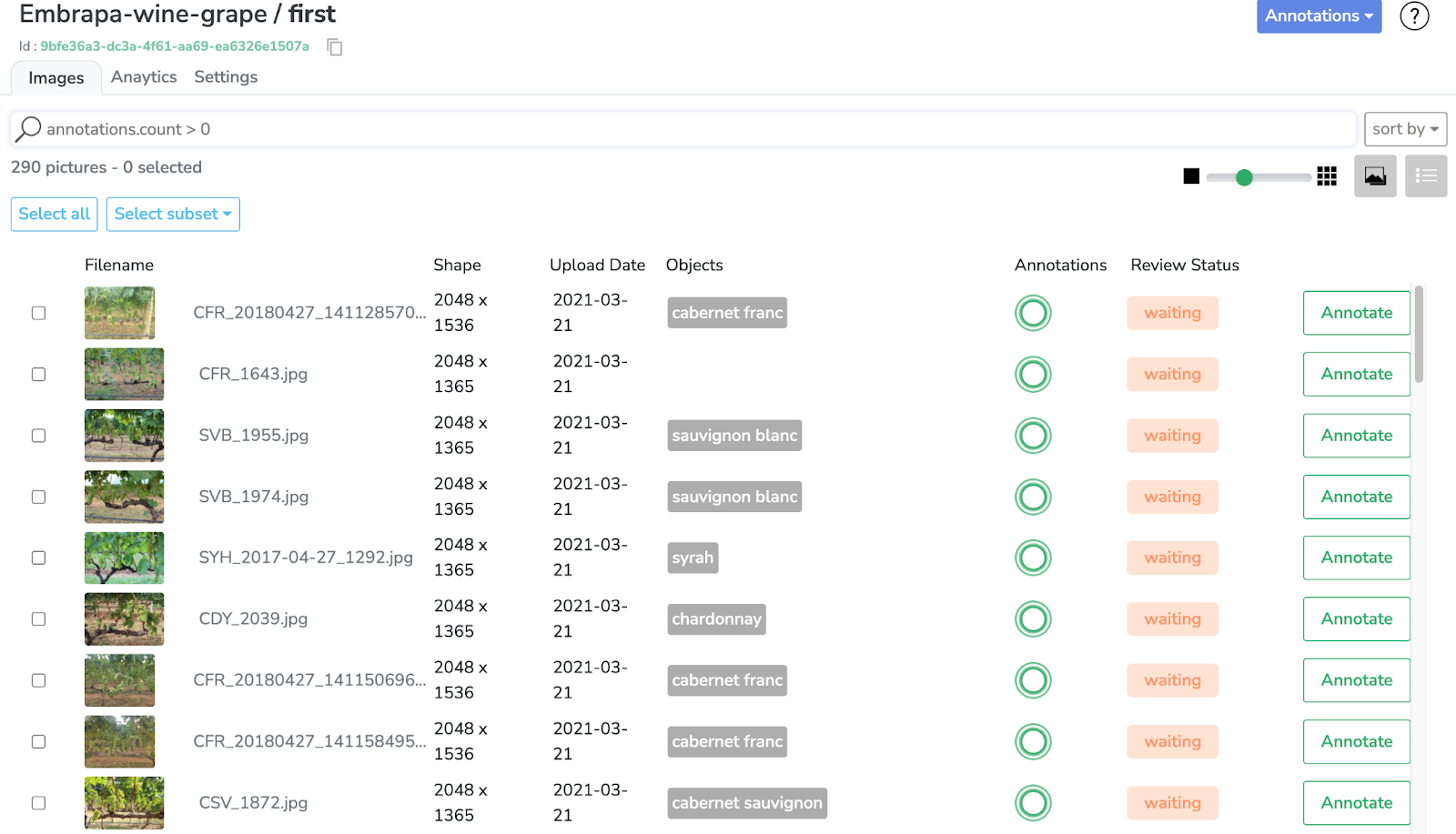
Comme vous pouvez le constater, le dataset est déjà entièrement annoté avec 5 classes différentes, correspondant à différents types de raisins.
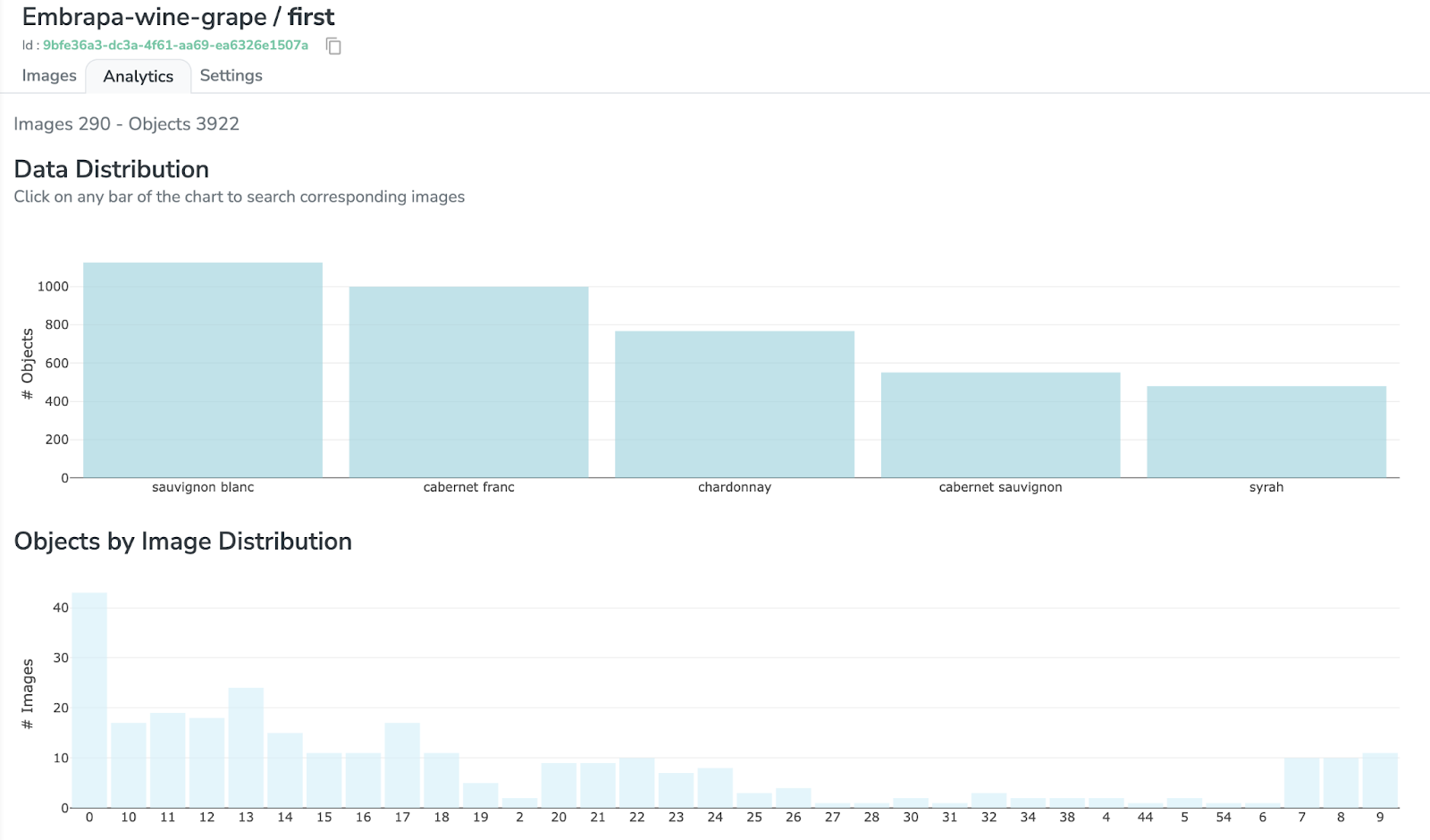
Si vous cliquez sur l'onglet "Analytics", vous pouvez avoir un meilleur aperçu de la "distribution des données" et "distribution d'objets par image" (entre autres métriques).
Jetons maintenant un œil aux annotations. Retour à l'onglet "Images", nous pouvons sélectionner tout le dataset, ou simplement un sous-ensemble des images que nous voulons labéliser.
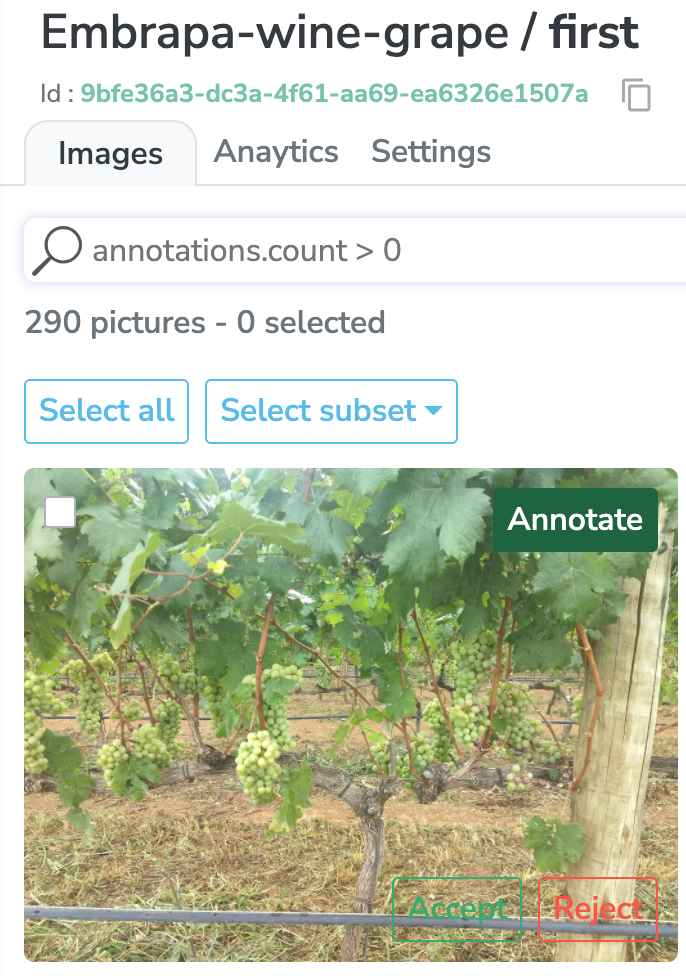
Notre plateforme est livrée avec un système pré-annoté et boîte à outils d'annotation IA robuste qui vous permettent d'automatiser entièrement vos annotations. De cette façon, vous ne pouvez conserver que les plus précis et optimiser votre ensemble d’entraînement.
Comme nous pouvons le voir ensuite, l'ensemble de données est bien annoté avec chaque raisin à l'intérieur des cadres de délimitation.

Vous pouvez sélectionner les images ou sous-ensembles que vous souhaitez, annoter, accepter, rejeter ou interagir par des commentaires et des mentions avec vos collègues. De cette façon, vous vous assurerez que tout le monde travaille sur les mêmes données. En passant, Picsellia est également livré avec un système de "Révision" (Review), dans lequel les collaborateurs désignés peuvent accepter ou rejeter les labels.

Maintenant, par souci de simplicité, nous ne créerons pas un modèle capable de détecter toutes ces 5 classes, mais plutôt un détecteur d'objets capable de détecter les raisins en général. Pour cela, nous allons fusionner les 5 classes en une seule que nous appellerons "raisin", et créer une nouvelle version du dataset avec.
Tout d'abord, je vais sélectionner toutes mes images et créer une nouvelle version du dataset sans labels ("Create a blank").

Une fois créé, je reviendrai au menu "datasets" dans la barre latérale et voyez ma dernière version sans label. Je peux voir que j'ai différentes versions de mon ensemble de données. Maintenant, choisissons notre nouvelle version : "raisin sans labels", afin de pouvoir configurer les labels et fusionner les différentes classes de raisin en une seule ("raisin").


Maintenant, pour paramétrer vos annotations, rendez-vous dans l'onglet "Settings" sur l'écran supérieur et sélectionnez “New labels”.
Ensuite, choisissez votre classe d'annotation – dans ce cas, Détection d'objets (Object Detection), nommez-la et ajoutez-la comme suit. Ensuite, cliquez sur “Create labels”.

Il est maintenant temps de fusionner nos labels !
Nous allons importer l'annotation de notre ancien dataset dans cette version et fusionner les 5 labels différents en un seul.
Pour cela, cliquez sur "Annotations", où nous sélectionnerons la version du dataset à partir duquel nous souhaitons importer nos labels. Dans ce cas, c’est le dataset appelé "first" qui contient les 5 raisins différents.
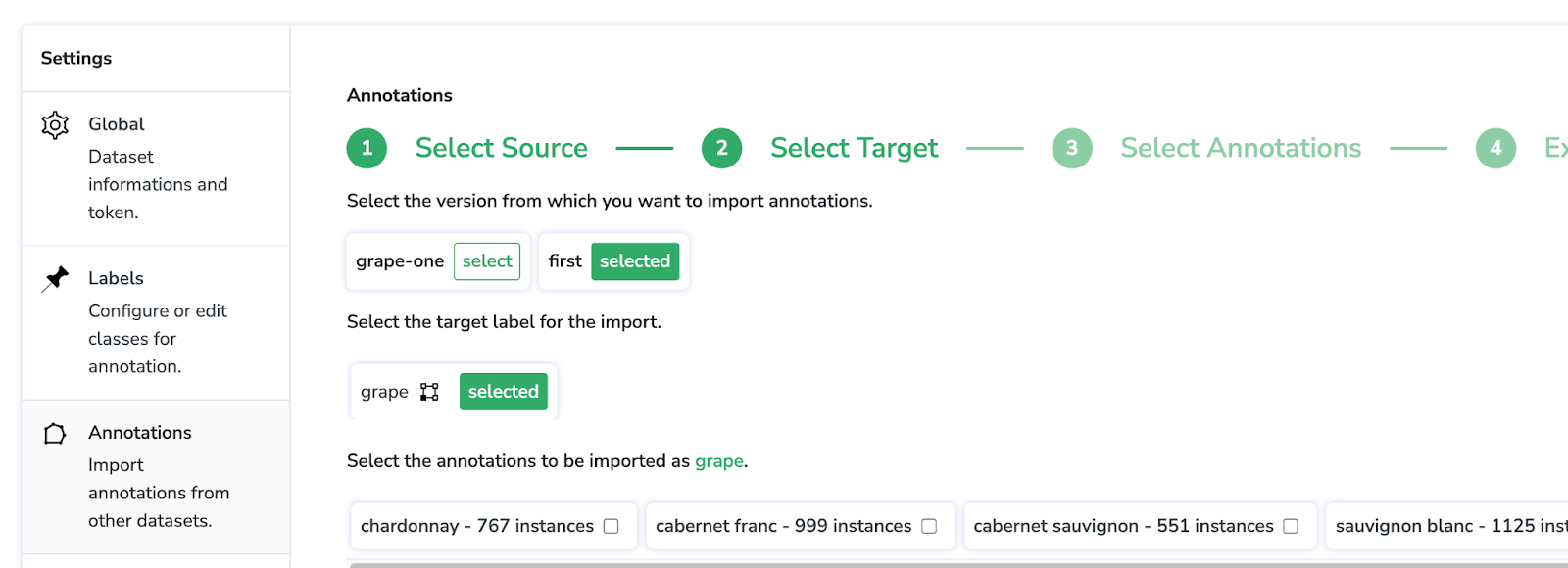
Choisissez le label de sortie "grape" comme indiqué ci-dessous et sélectionnez chacune des annotations à importer en tant que "grape" en cochant leurs cases. Ensuite, cliquez sur “Execute instructions”.

Si nous allons au tag "Settings", nous pouvons voir que notre label est bien défini comme un seul "grape", et voir qu'il contient les 3 920 objets.

Retour à l'interface du dataset (ongle "Images"), on voit juste un label.
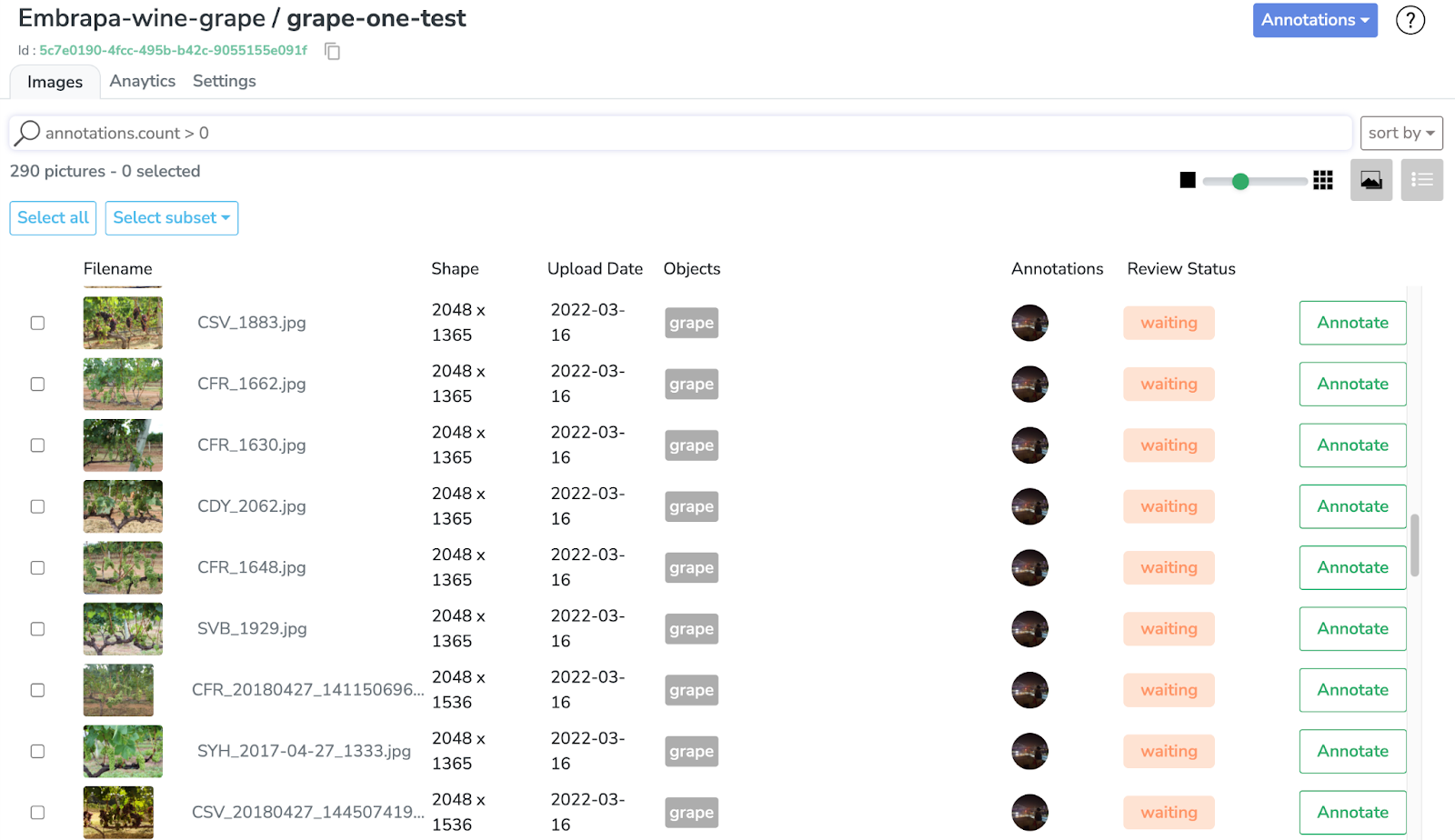
Si nous regardons les annotations, nous pouvons observer que toutes nos bounding boxes contiennent tous les différents types de raisins, désormais étiquetés simplement "grape".

Passons maintenant aux choses sérieuses : former un YOLOv5 sur cet ensemble de données.
2. Mettre en place l'entrâinement
Nous allons créer un nouveau projet nommé "yolo-grape-test", qui utilise cet ensemble de données et organise mes entraînements.
Chez Picsellia, vous avez également la possibilité d'inviter des membres de l'équipe dans votre projet pour travailler sur les mêmes données (nous allons l'ignorer pour ce tutoriel).
Pour mémoire, dans l'onglet “All Projects” ("Tous les projets"), dans le menu de la barre latérale, vous verrez tous vos projets stockés au même endroit.
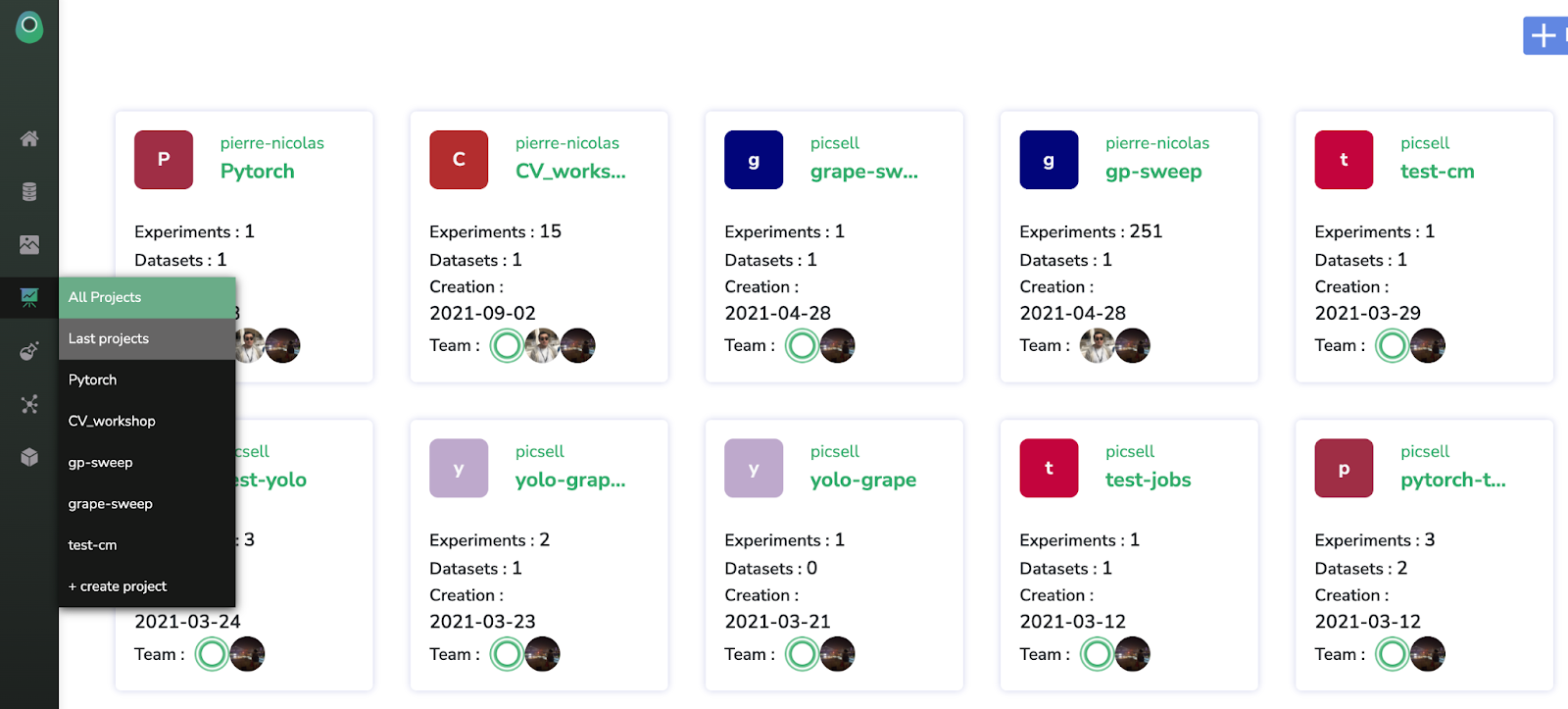
Maintenant, vérifions notre projet. À ce stade, le projet est assez vide, nous allons donc joindre le dataset que nous venons de créer à ce projet, en cliquant sur "Open Datalake".
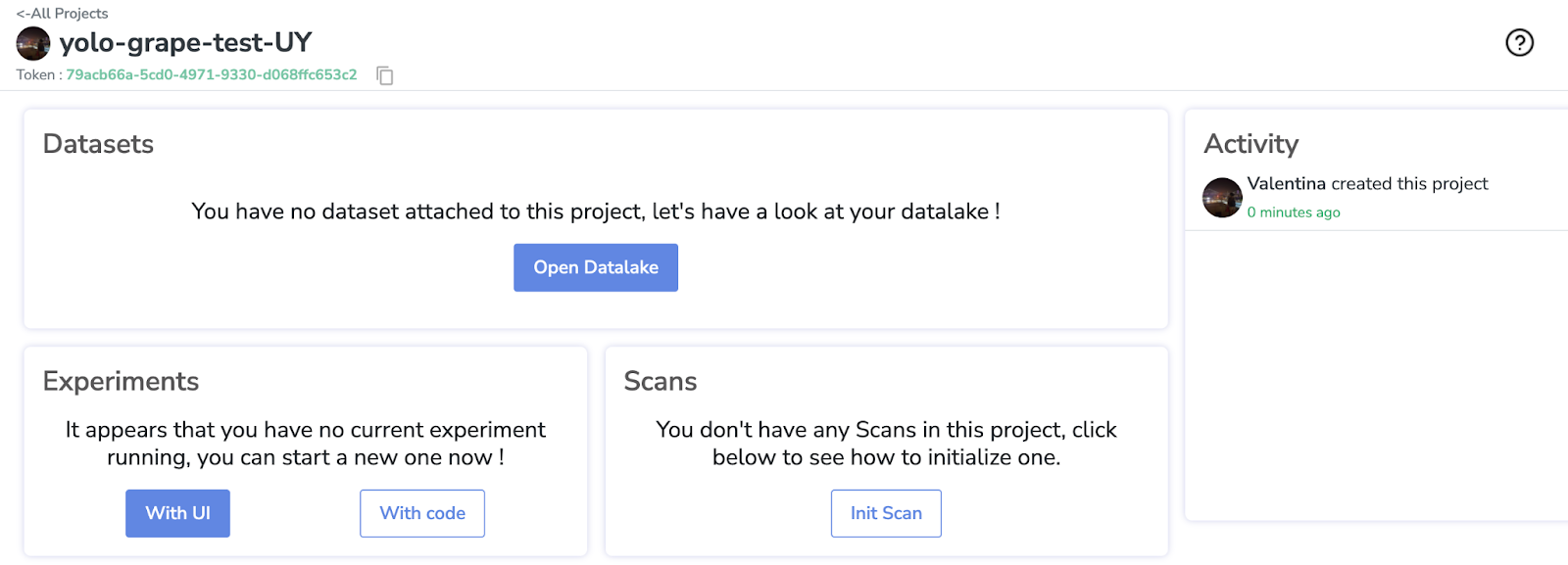
Nous sélectionnons ensuite le projet souhaité, "Embrapa-wine-grape".

Et nous voulons choisir la version "grape-one".
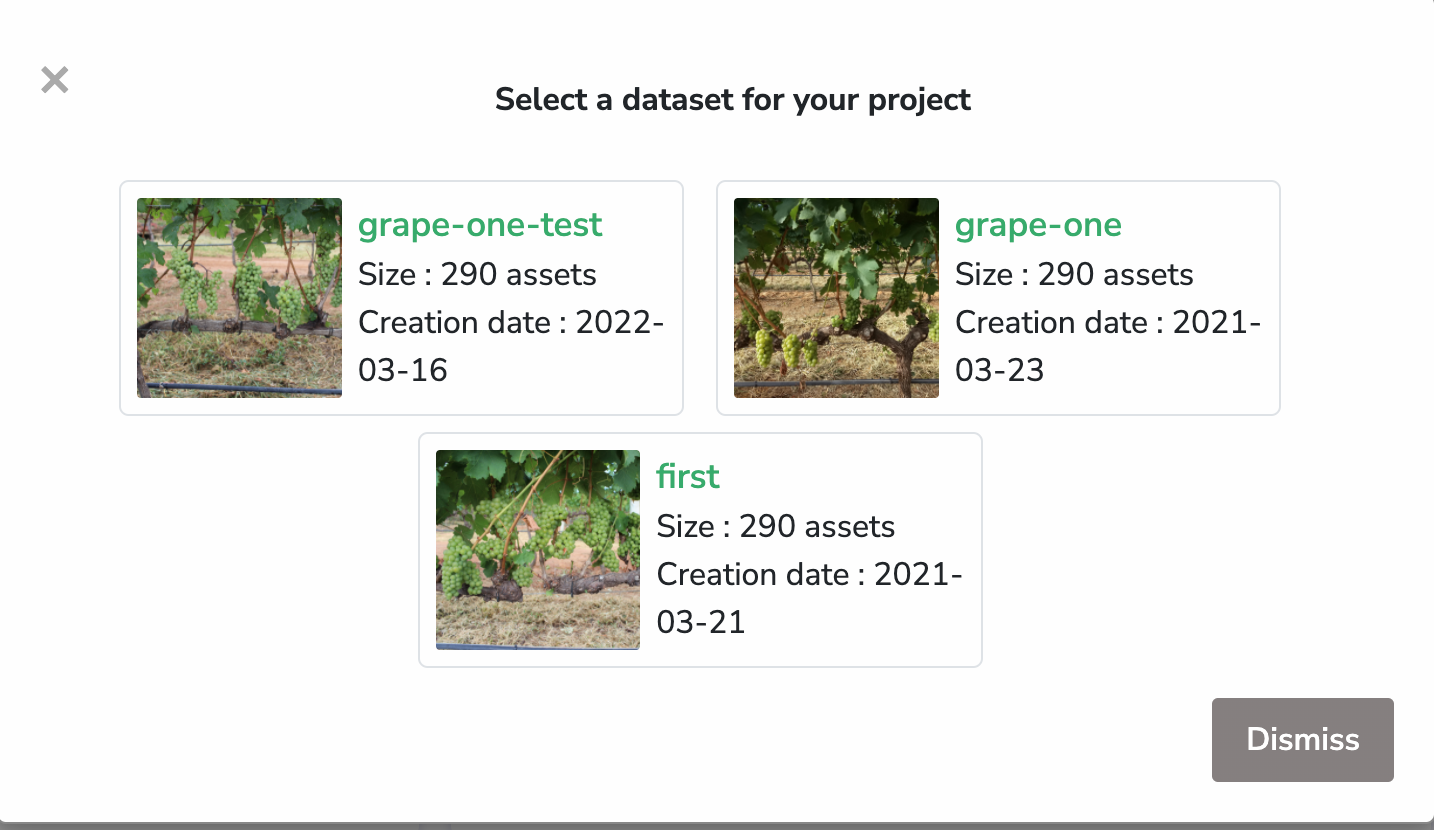
Notre dataset est désormais bien attaché !
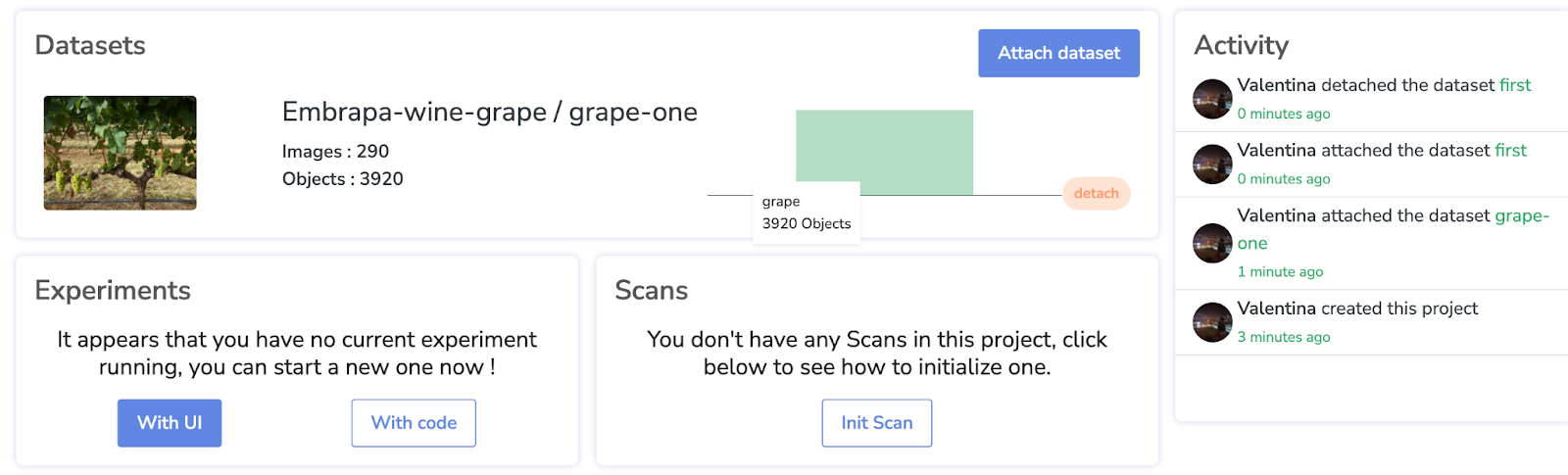
Ensuite, avant de créer notre expérience, examinons la section "Models" (Modèles) de Picsellia.
Sur cette page, vous pouvez trouver tous les modèles que nous avons ajoutés et qui constituent une architecture de base que vous pouvez utiliser pour lancer votre expérience, comme indiqué ci-dessous.
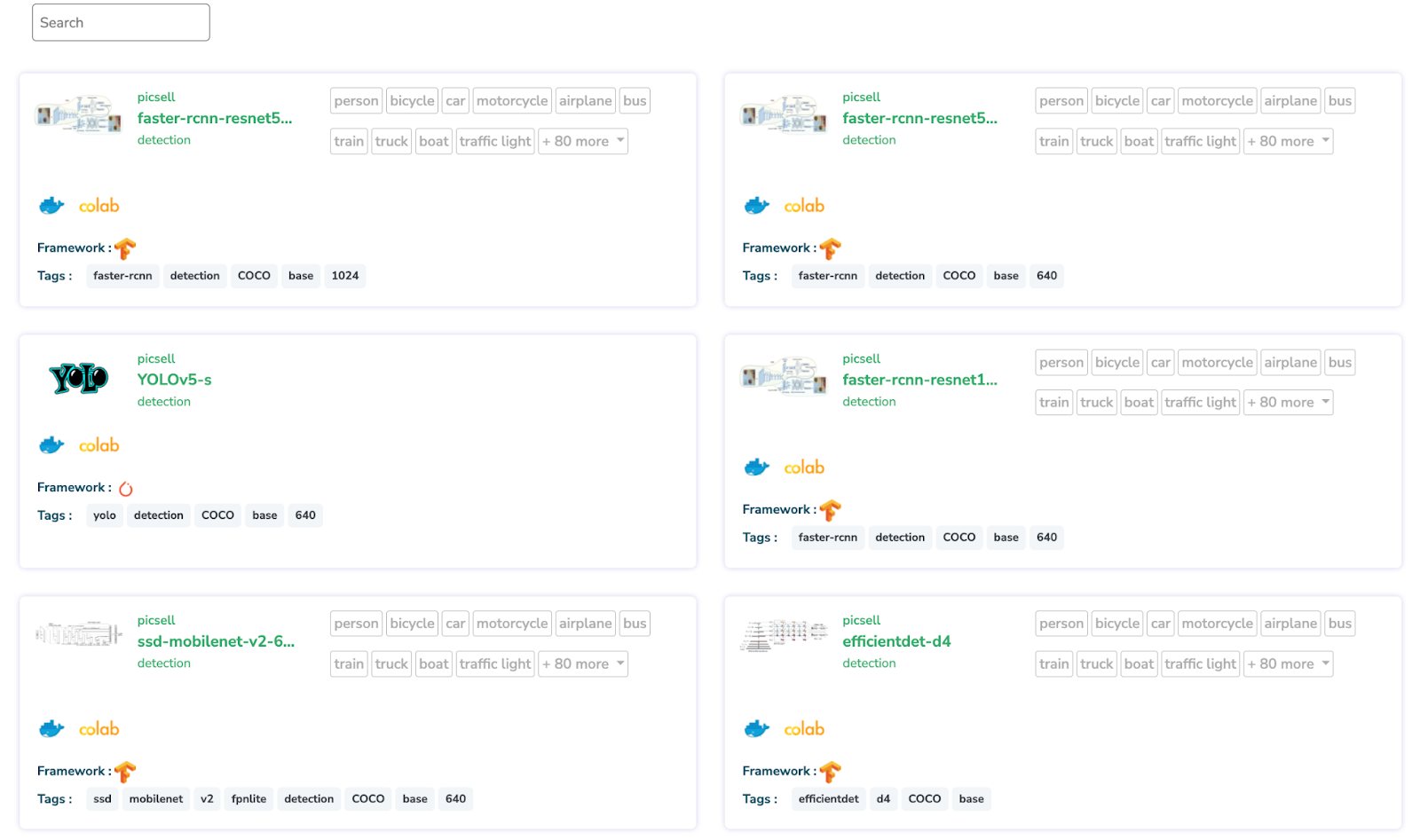
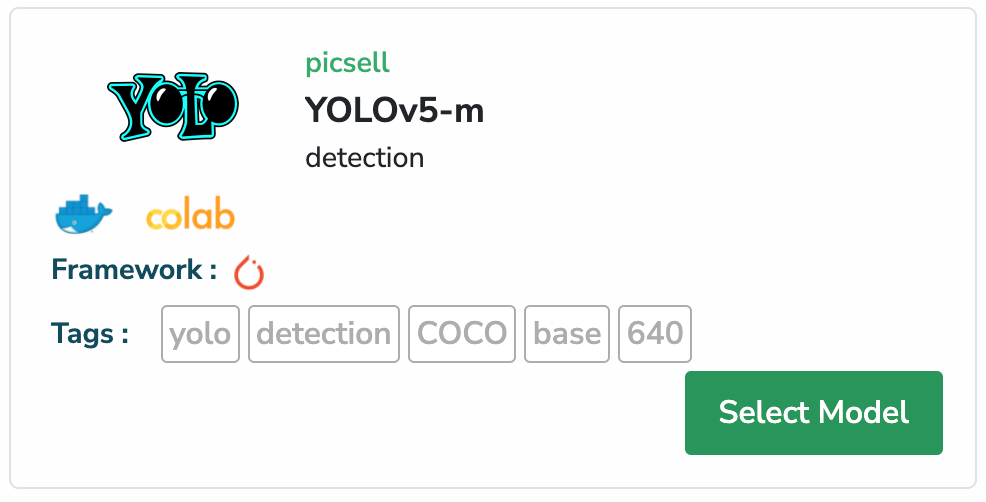
Pour notre expérience, nous allons utiliser le modèle YOLOv5-m, en raison de sa rapidité de d’entraînement. Vous pouvez utiliser ce modèle immédiatement, ce qui signifie que vous n’avez rien à faire, il suffit de les sélectionner.
Il est maintenant temps de revenir à notre projet, et créez notre expérience en utilisant ce modèle YOLOv5-m pré-entraîné.
Une fois sur place, nous allons lancer notre expérience avec l’interface utilisateur.
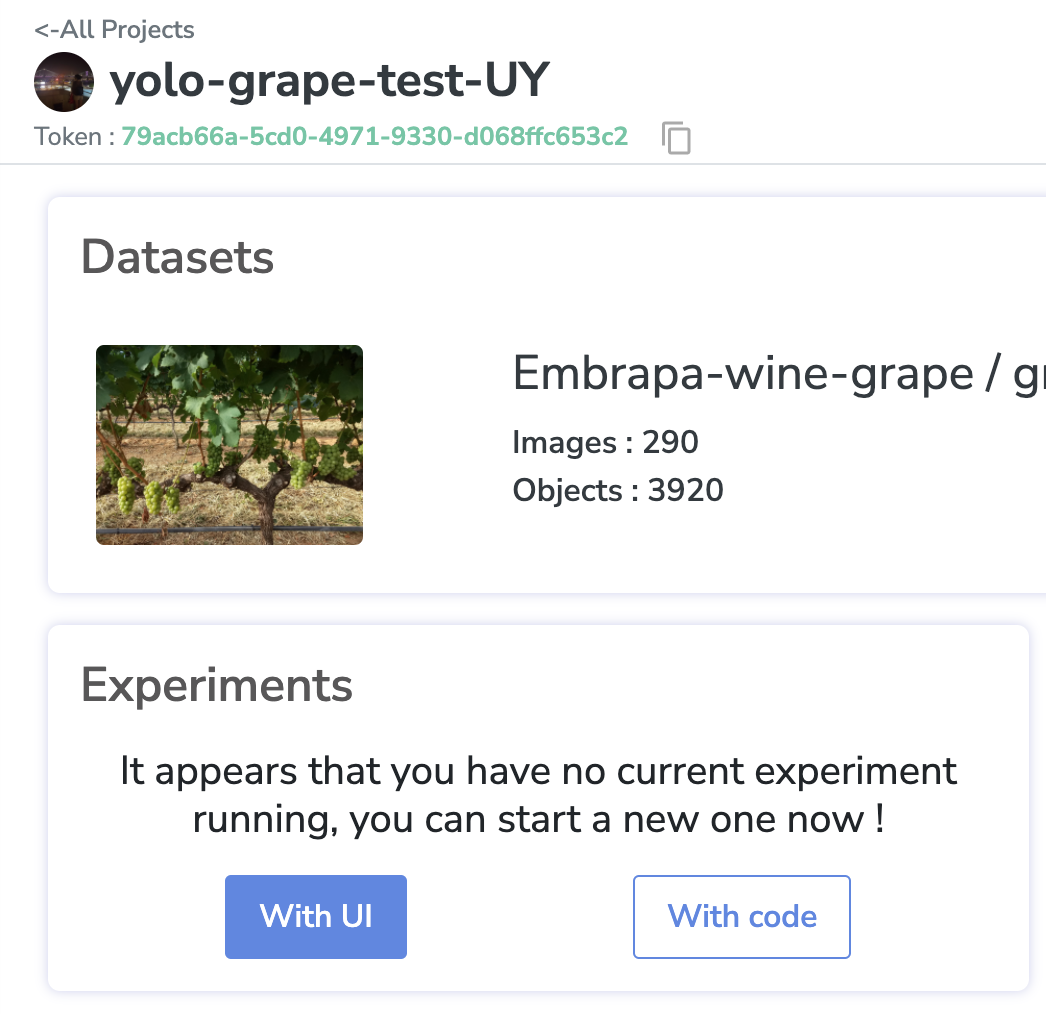
Ce sera la première version de notre entraînement, nommée "v1".
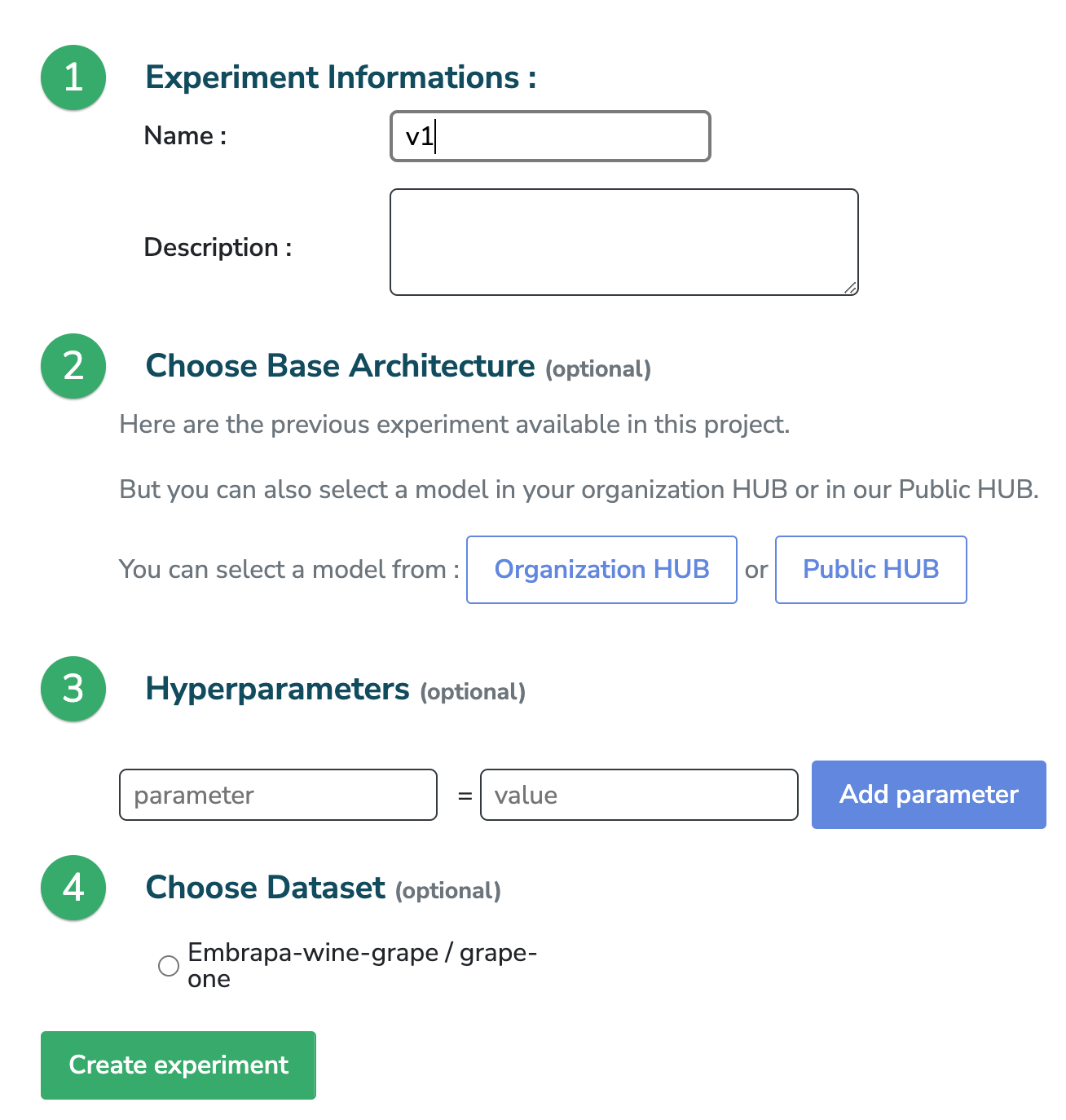
Et, dans un deuxième temps, nous allons choisir le modèle d'architecture de base de mon "Organisation HUB". Dans ce cas, YOLOv5-m.
Pour exécuter YOLOv5-m, il suffit de configurer deux paramètres. Le nombre d'étapes (ou "epochs") et la taille du lot.
Pour ce tutoriel, et pour le montrer rapidement, nous configurons simplement 100 epochs. Comme nous l'exécuterons dans Colab, nous allons configurer une petite taille de lot, 1, juste pour le test ; et exécutez-le sur un gros matériel plus tard.

Enfin, nous sélectionnons notre dataset.
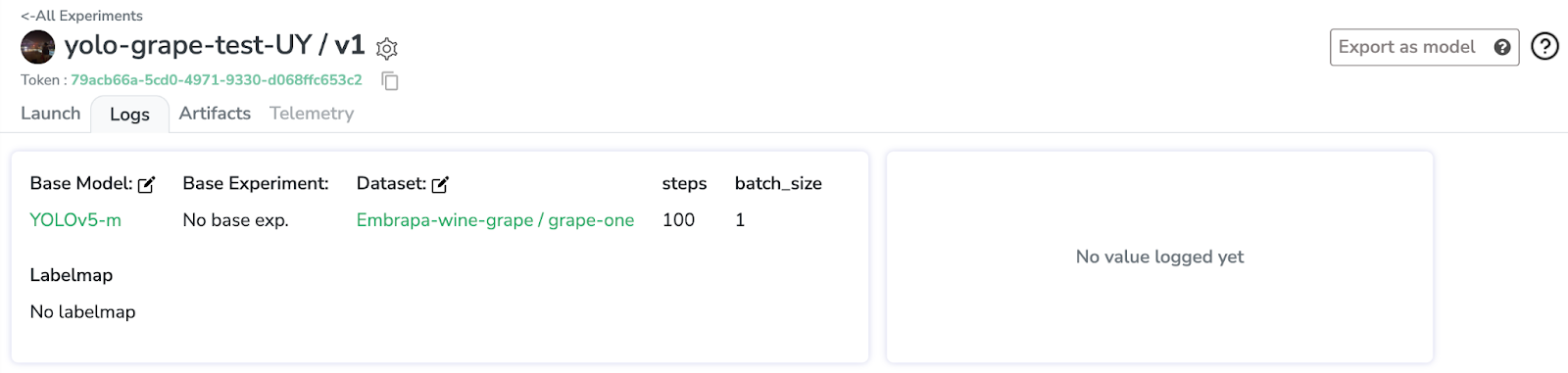
Ensuite, nous créons l’expérience et nous verrons l’aperçu de l’expérience. Nous avons notre modèle de base, notre dataset joint et nos paramètres sont tous configurés.
La beauté de Picsellia est que dans l'ongle "Launch" (Lancement), nous pouvons choisir différentes manières de lancer nos expériences.
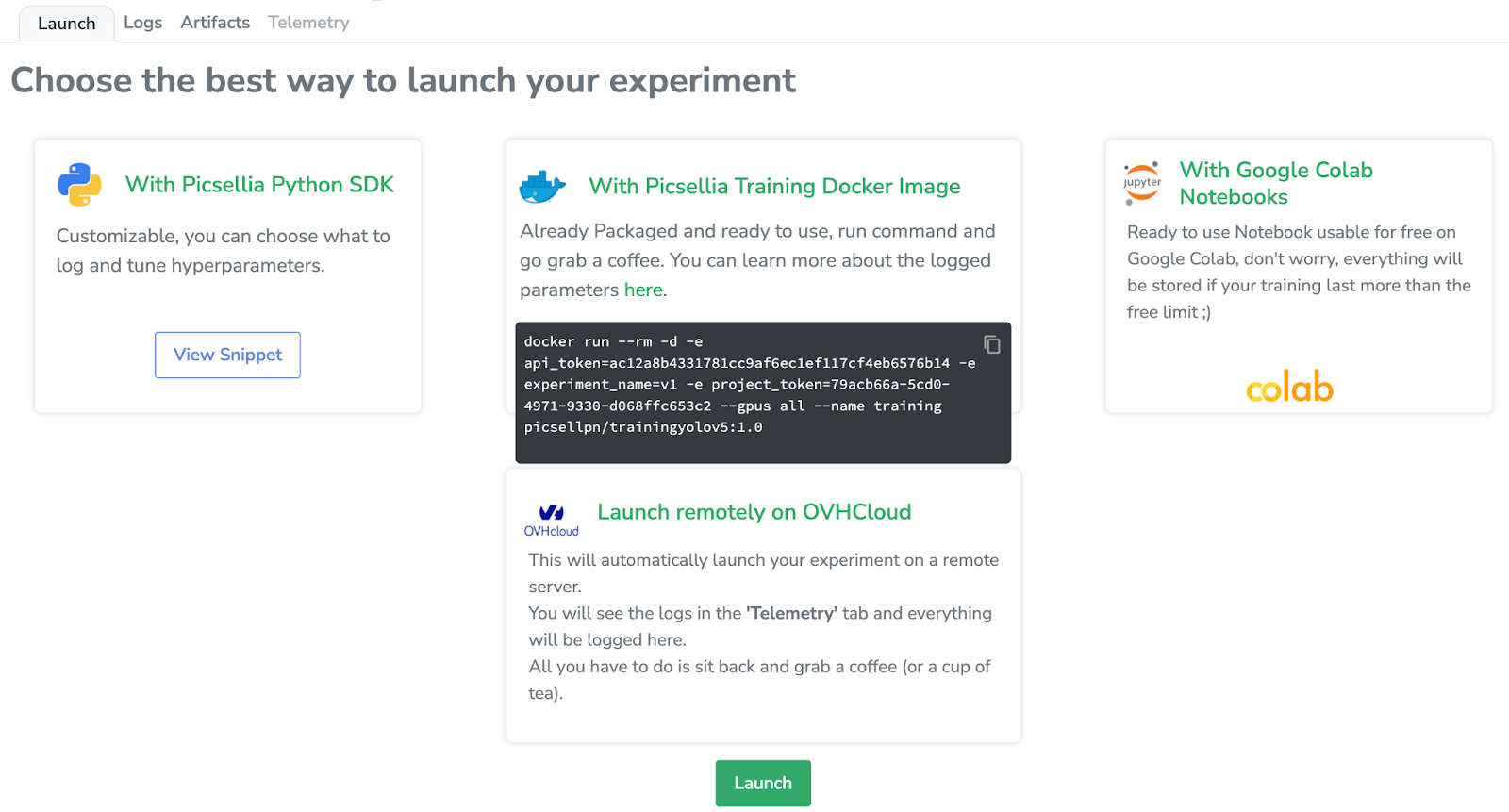
Nous allons le lancer avec Google Colab, donc en cliquant ici, nous accéderons à un notebook Jupyter préconfiguré avec tout le nécessaire pour former un YOLOv5. Je vais vous montrer rapidement toutes les étapes nécessaires pour lancer l'entraînement.
3. Lancement de l'entraînement
Tout d’abord, nous devons installer le package Picsellia, ainsi que le package Picsellia YOLOv5. Dans cette bibliothèque, nous avons regroupé toute l'implémentation Pytorch de YOLOv5.

Nous devons importer les packages avec Pytorch, os, sous-processus, etc.
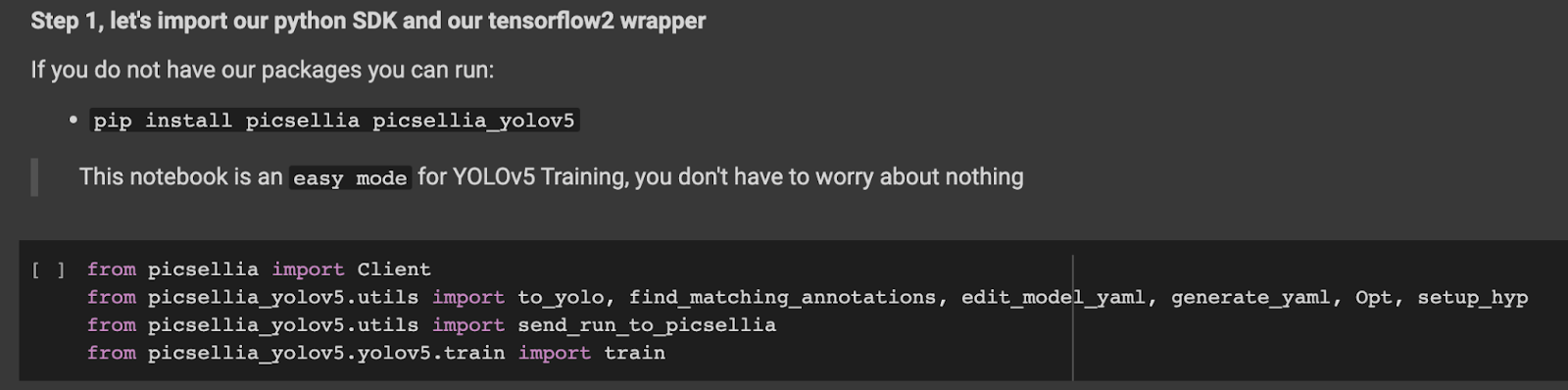
Nous devons tirer parti du système d'expérimentation de Picsellia pour obtenir tous les fichiers dont nous disposons à partir de notre travail pré-entraîné et les paramètres, afin qu'avec la vérification, nous puissions tout obtenir sur l'instance.


Ensuite, nous devons télécharger les annotations et les images.
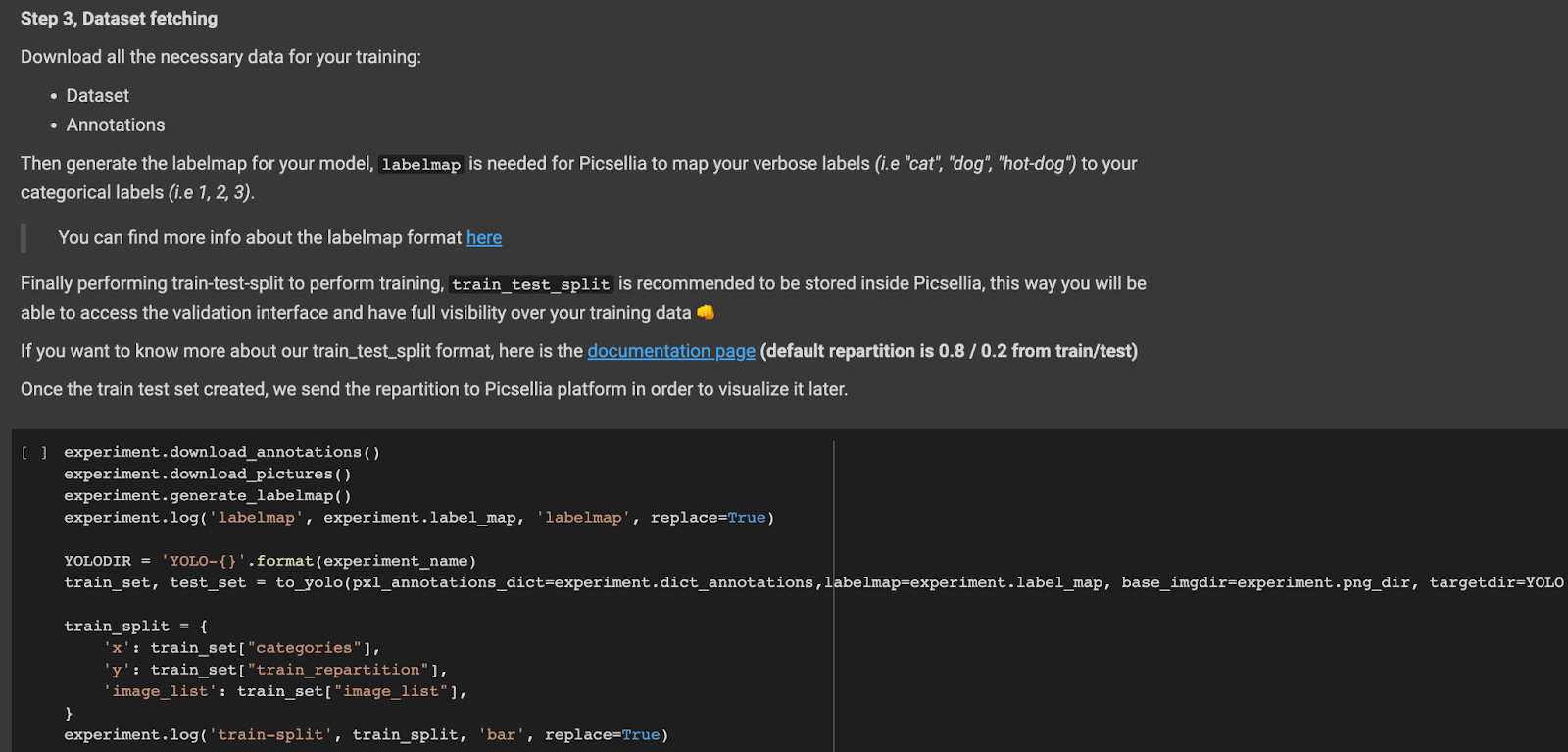
Nous mettons en place un répertoire qui stockera nos images et annotations.


Nous devons ensuite générer un yaml qui contiendra la carte des labels ainsi que le répertoire, le chemin de l'entraînement et les images de test.

Ensuite, nous devons configurer les hyperparamètres qui seront utilisés pour l'entraînement, donc les seules choses que nous devons donner sont les paramètres que nous avons configurés à partir de Picsellia, la carte des labels et le nom de l'expérience.

Et ensuite, nous pouvons enfin lancer l'entraînement !


Nous l'avons déjà lancé afin de vous le montrer, car il peut être assez lent sur un notebook CPU Jupyter. Mais comme vous pouvez le constater, l'entraînement se déroule plutôt bien.

Et tout est renvoyé à Picsellia, en direct !
Comme vous pouvez le voir ensuite, j'ai déjà mes métriques d'entraînement en direct sur la plateforme. Si je rafraîchis la page, je devrais avoir quelques valeurs supplémentaires, avec les nouvelles epochs.
4. Vérifiez les résultats
Maintenant, comme il serait trop long d'attendre la fin de l'entraînement, et pour vous montrer de vrais résultats avec un entraînement plus long, j'ai mis en place un autre entraînement que je vous montrerai ensuite.

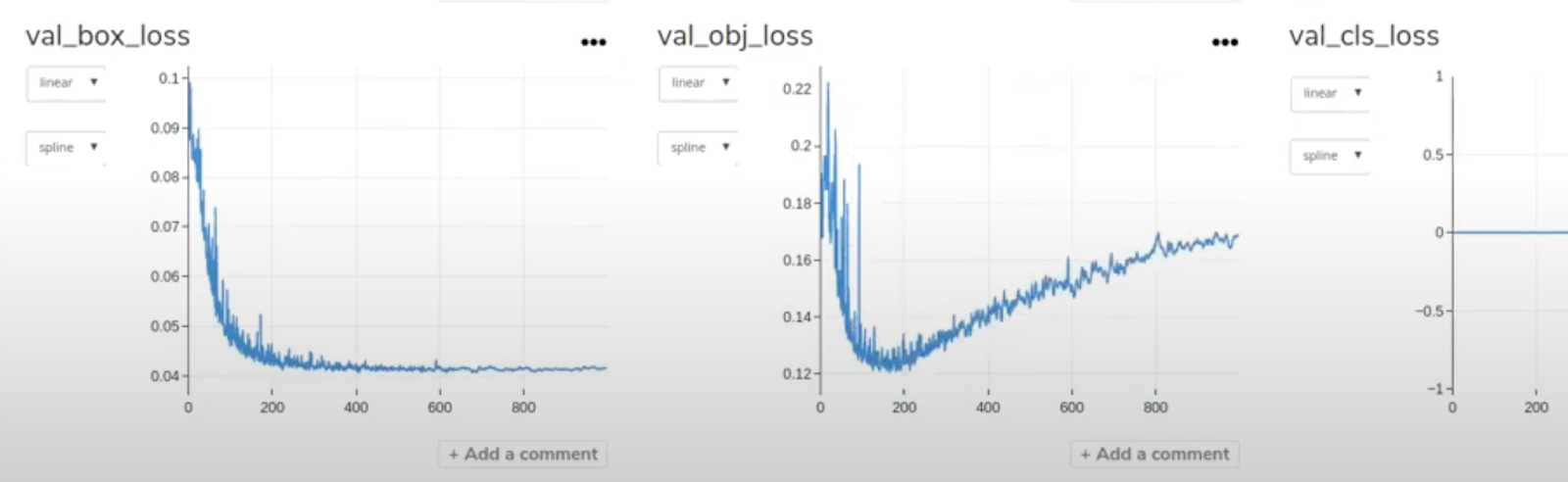
Cet entraînement comporte 1 000 epoch, car il a été entraîné sur les GPU NVIDIA v100. Comme vous pouvez le constater, les statistiques sont plutôt bonnes.

Nous avons des problèmes avec notre loss ici – nous devrions y réfléchir plus tard –, mais comme vous pouvez le voir, elle converge un peu.
Voyons maintenant les résultats avec une évaluation sur des images réelles de dataset. Pour cela, j'ai enregistré les images de mon évaluation sur différents lots d'images.
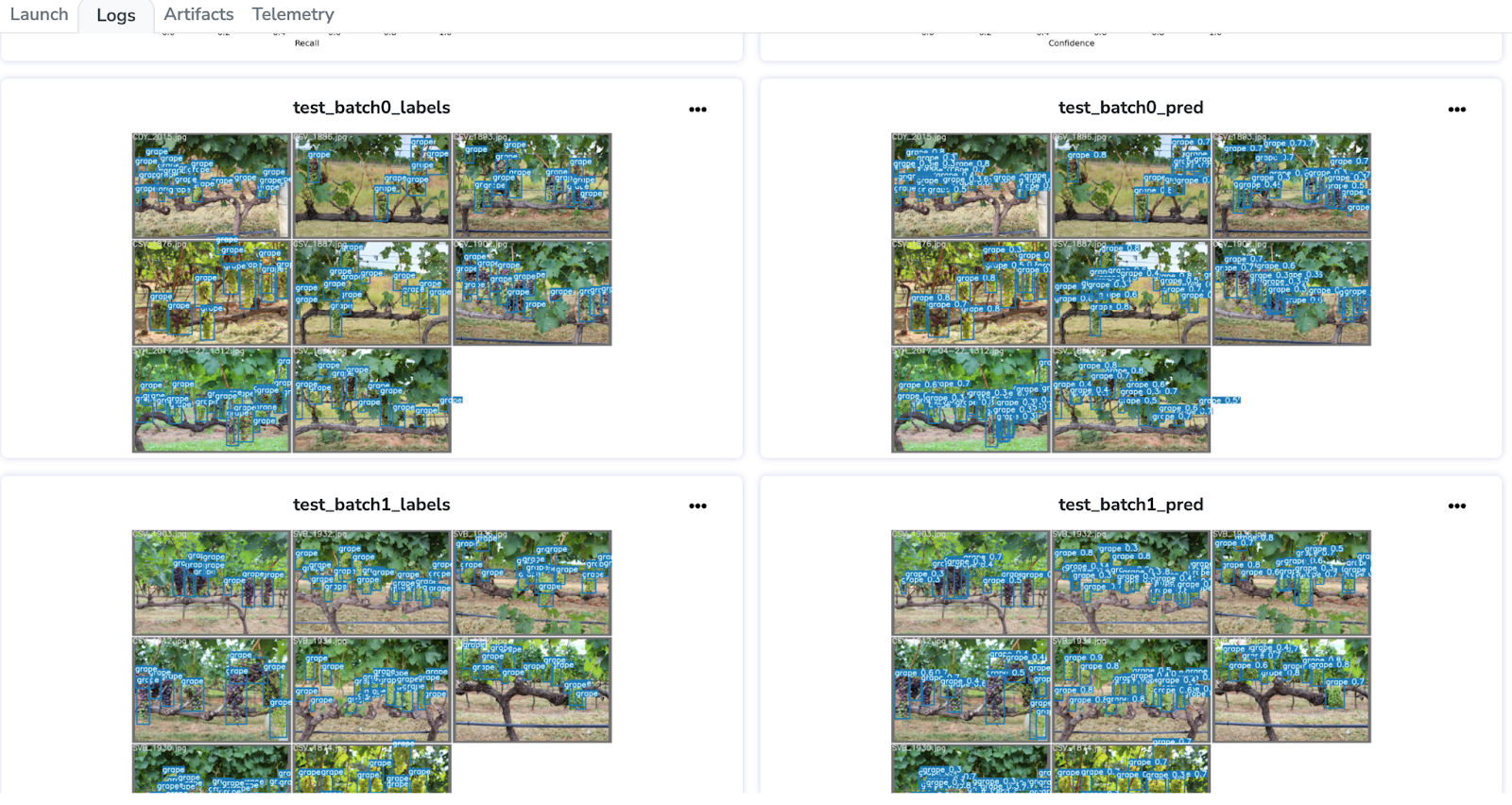
J'ai téléchargé une de ces images. Nous avons déjà d’excellents résultats pour notre excellent algorithme de détection !

À titre d'exemple, si nous effectuions seulement 1 000 epochs (ou "étapes") d'entraînement, l'ensemble du processus d'entraînement pourrait prendre jusqu'à 4 heures. Alors que, pour notre test initial, où nous n’avions défini que 100 epochs, cela ne pouvait prendre que quelques minutes.

Si nous vérifions les fichiers de notre expérience, nous avons réussi à télécharger tous les fichiers nécessaires pour reprendre notre entraînement plus tard. Nous avons besoin du fichier de configuration, qui est le yaml ; un fichier de point de contrôle pour l'hyperparamètre ; et un autre fichier de point de contrôle qui correspond aux poids (weights) pytorch.
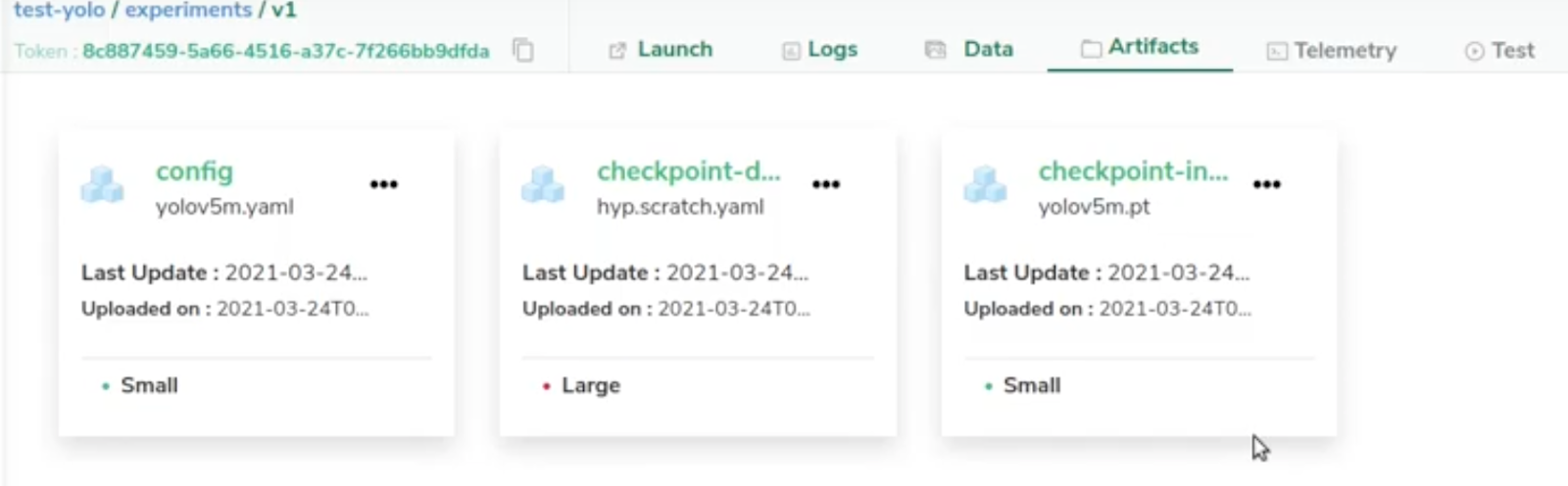
Désormais, nous pouvons reprendre notre entraînement quand nous le souhaitons et répéter nos expériences encore et encore facilement en utilisant Picsellia !
Si vous souhaitez essayer Picsellia et tirer parti de nos dernières fonctionnalités MLOps (déploiement de modèles, surveillance, orchestration automatisée des pipelines, etc.), demandez votre essai ici!



